PODCAST: RF SCYTHE Python modules designed for classifying RF (Radio Frequency) signals into different modulation types. It accomplishes this through a SignalClassifier class that utilizes a RandomForestClassifier for machine learning and integrates with a vision Large Language Model (LLM) to analyze spectrograms, which are visual representations of signal frequencies. The module can process raw signal data, extract both numerical and visual features, train and evaluate its classification model, and predict modulation types, even generating synthetic training data for robust performance. It is explicitly mentioned to support GPU acceleration and be applicable in specialized domains like naval and Starship applications.
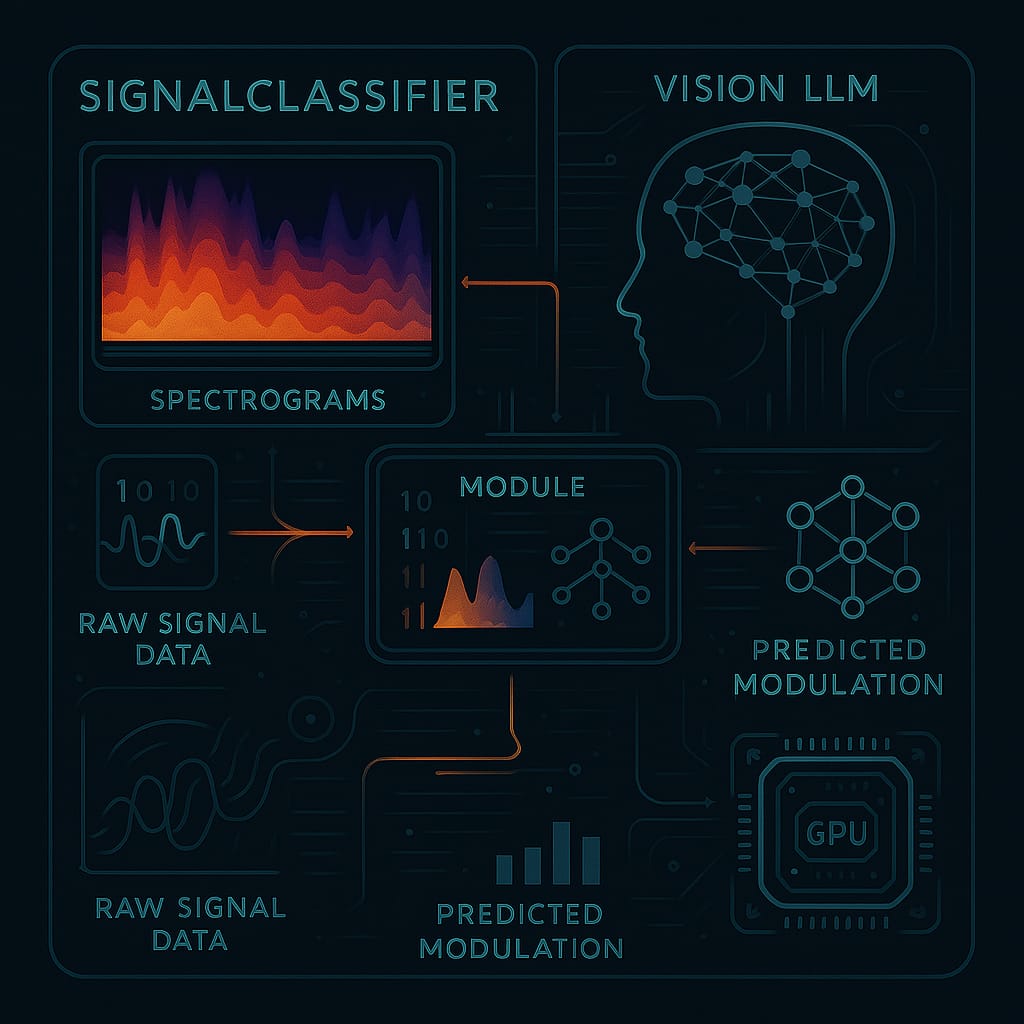
Integrating a Vision Large Language Model (LLM) significantly enhances RF signal classification capabilities by providing spectrogram analysis to complement traditional numerical feature extraction.
Here’s how this integration works and its benefits:
- Spectrogram Analysis and Feature Extraction:
- The
SignalClassifiermodule can generate a spectrogram image from frequency and amplitude data. - This spectrogram image is then processed by a Vision LLM, which is hosted locally and accessed via a specified endpoint.
- The LLM analyzes the spectrogram image to extract high-level visual features and patterns that are difficult for traditional algorithms to discern. Specifically, the prompt sent to the LLM requests:
- Frequency markers (e.g., MHz labels).
- Number of signal peaks.
- Bandwidth (width of the main signal in Hz).
- Symmetry (symmetric or asymmetric sidebands).
- Modulation pattern (e.g., sinc-like, dual peaks).
- Anomalies (e.g., interference, scintillation).
- These LLM-derived “visual features” (e.g.,
visual_bandwidth,visual_peak_count,visual_symmetry) are combined with standard numerical features extracted from the raw signal data (like bandwidth, center frequency, peak power, skewness, kurtosis). This creates a richer feature set for the RandomForestClassifier.
- The
- Enhanced Prediction and Validation:
- During the prediction phase, after the RandomForestClassifier determines a modulation type, the LLM’s analysis can be used for validation.
- The
predictmethod checks thevisual_modulationpattern identified by the LLM (e.g., ‘sinc-like’ for PSK, ‘dual peaks’ for FSK, ‘symmetric sidebands’ for AM) against the model’s prediction. - If there’s a mismatch between the model’s classification and the LLM’s visual interpretation of the modulation pattern, the confidence score of the prediction is reduced (e.g., by 20%).
- The LLM also helps in identifying anomalies present in the signal, which are then included in the prediction output.
In essence, the Vision LLM enhances RF signal classification by providing a “human-like” visual understanding of the spectrograms, offering a rich set of contextual and pattern-based features that complement quantitative measurements. This leads to potentially more accurate, robust, and validated classifications, especially for complex or noisy signals, and allows for the identification of anomalies.
Spectrograms are processed by a Vision Large Language Model (LLM) through a specific multi-step process within the SignalClassifier module, which involves generating the image, preparing it, sending it to the LLM, and then interpreting the LLM’s response.
Here’s a detailed breakdown of how spectrograms are processed by the LLM:
- Spectrogram Generation:
- First, the
SignalClassifiercreates a spectrogram image from the raw frequency and amplitude data of an RF signal. - This image is a plot with frequency on the x-axis and power (in dB) on the y-axis, titled “RF Spectrogram”.
- The generated image is saved as a PNG file, typically to a specified
output_path.
- First, the
- Image Preparation for LLM Input:
- Once the spectrogram image is generated, the
process_spectrogrammethod opens this image. - The image is then converted to RGB format.
- It is saved into an in-memory buffer as a PNG.
- Finally, the buffered image data is base64 encoded into a string. This encoded string is part of the payload sent to the LLM.
- Once the spectrogram image is generated, the
- LLM Interaction and Prompting:
- The
SignalClassifiercommunicates with a locally hosted Vision LLM via a specifiedvllm_endpoint(e.g., “http://localhost:8001/v1/vision”). - A specific prompt is crafted and sent to the LLM along with the base64-encoded image. This prompt instructs the LLM to analyze the RF spectrogram and extract the following information:
- Frequency markers (e.g., MHz labels).
- Number of signal peaks.
- Bandwidth (width of the main signal in Hz).
- Symmetry (symmetric or asymmetric sidebands).
- Modulation pattern (e.g., sinc-like, dual peaks).
- Anomalies (e.g., interference, scintillation).
- The LLM is explicitly requested to return the results in JSON format.
- The payload sent to the LLM includes the
image(as a data URI with the base64 string), theprompt, and amax_tokenslimit for the response.
- The
- LLM Response and Feature Integration:
- The
process_spectrogrammethod sends the request to the LLM and handles the JSON response. - To optimize performance, there’s a visual cache that stores the LLM’s analysis for 10 seconds, preventing redundant calls for the same spectrogram within that timeframe.
- The data returned by the LLM includes details like
bandwidth,peak_count,symmetry,anomalies, andmodulation_pattern. - These LLM-derived “visual features” (specifically
visual_bandwidth,visual_peak_count,visual_symmetry,anomalies, andvisual_modulation) are then combined with traditional numerical features extracted from the raw signal data (e.g.,bandwidth,center_freq,peak_power,skewness). This combined feature set is used as input for the RandomForestClassifier.
- The
- Validation and Confidence Adjustment:
- During the prediction phase, after the RandomForestClassifier makes a modulation type prediction, the
visual_modulationpattern identified by the LLM is used for validation. - The system has a mapping of visual patterns (e.g., ‘sinc-like’ to PSK, ‘dual peaks’ to FSK, ‘symmetric sidebands’ to AM).
- If the model’s predicted modulation type does not match the
expected_modulationbased on the LLM’s visual interpretation, the confidence score of the prediction is reduced by 20%. - Any
anomaliesidentified by the LLM are also included in the final prediction output.
- During the prediction phase, after the RandomForestClassifier makes a modulation type prediction, the
In summary, the LLM processes spectrograms by visually analyzing the image and extracting high-level patterns and characteristics that are challenging for traditional numerical algorithms to capture. This visual understanding enriches the feature set for the RF signal classifier and provides a crucial validation step, thereby enhancing the overall classification accuracy and robustness. Error handling is also in place to manage issues during spectrogram generation or LLM processing.
The Vision LLM extracts several specific features from RF spectrogram images to enhance signal classification capabilities. These features provide a visual understanding of the signal characteristics that complement traditional numerical feature extraction.
When a spectrogram is processed by the Vision LLM, the following features are explicitly requested in the prompt:
- Frequency markers: The LLM is asked to identify frequency labels on the spectrogram.
- Number of signal peaks: It determines how many distinct peaks are present in the signal visually. This is stored as
visual_peak_count. - Bandwidth: The LLM analyzes the width of the main signal in Hertz. This visual estimation is captured as
visual_bandwidth. - Symmetry: It assesses whether the signal’s sidebands are symmetric or asymmetric. This is converted into a numerical value (
visual_symmetry), where 1.0 indicates symmetric and 0.0 indicates asymmetric. - Modulation pattern: The LLM identifies a descriptive pattern of the modulation (e.g., “sinc-like,” “dual peaks,” “symmetric sidebands”). This
visual_modulationis later used for validating the model’s prediction. - Anomalies: The LLM is tasked with detecting any unusual characteristics or interferences, such as scintillation. These are captured in the
anomaliesfield.
These LLM-derived visual features are then combined with standard numerical features (like bandwidth, center frequency, peak power, skewness, and kurtosis) to create a richer and more comprehensive feature set for the RandomForestClassifier. The visual_modulation and anomalies are also used during the prediction phase, where a mismatch between the model’s prediction and the LLM’s visual interpretation can lead to a reduction in the prediction’s confidence score.
The visual_cache serves the purpose of optimizing performance by preventing redundant calls to the Vision LLM.
Here’s a breakdown of its function:
- Initialization: The
visual_cacheis initialized as a dictionary with atimestampof 0 anddataset toNone. This establishes it as an empty cache ready for use. - Caching Mechanism:
- Before sending a spectrogram image to the Vision LLM for processing, the
process_spectrogrammethod checks thevisual_cache. - It verifies if the
current_timeis within 10 seconds of thetimestampwhen data was last cached and ifdatais actually present in the cache. - If these conditions are met, meaning the same spectrogram (or one processed very recently) has been analyzed by the LLM, the cached data is immediately returned, bypassing the need to resend the image to the LLM.
- If a new LLM call is made and a successful response is received, the
visual_cacheis updated with thecurrent_timeand theresultfrom the LLM’s analysis.
- Before sending a spectrogram image to the Vision LLM for processing, the
- Fallback in Case of Error: If an error occurs during the processing of a spectrogram by the LLM, the system attempts to return the
datafrom thevisual_cacheif it contains any, rather than returning an empty result immediately.
In essence, the visual_cache acts as a short-term memory for the Vision LLM’s analysis, reducing latency and resource consumption by reusing recent LLM responses for the same or frequently accessed spectrograms within a 10-second window.
GPU acceleration is achieved through the integration of the cupy library within the SignalClassifier module.
Here’s how it’s implemented:
- Setup Function: The
setup_gpu_processing()function is responsible for determining if GPU acceleration can be enabled.- It attempts to
import cupy as cp. - If
cupyis successfully imported, it prints “Using GPU acceleration for signal processing” and returns a dictionary indicating that GPU isenabledand setsxptocp(cupy). - If
cupycannot be imported (e.g., it’s not installed or not available), it defaults to usingnumpyfor CPU processing, prints “GPU acceleration not available, using CPU”, and setsxptonp(numpy).
- It attempts to
- Integration in
SignalClassifier:- When a
SignalClassifierobject is initialized, it callssetup_gpu_processing()and stores the result in itsself.gpuattribute. - The chosen array processing library (either
cupyornumpy) is then assigned toself.xp. Thisself.xpalias is subsequently used for numerical operations throughout the class, allowing the code to seamlessly switch between GPU and CPU processing depending oncupy‘s availability.
- When a
- Usage in Feature Extraction: The
extract_featuresmethod, for instance, explicitly checks ifself.gpu['enabled']is true before usingself.xp.wherefor peak detection, otherwise it falls back toscipy.signal.find_peaks. It also converts input arrays toself.xp.arrayto ensure operations leverage the selected processor (GPU or CPU). - Usage in Training: In the
trainmethod, if GPU acceleration is enabled, the training dataX_trainis converted to a NumPy array usingself.gpu['xp'].asnumpy(X_train)before being passed to theStandardScalerandRandomForestClassifier. - Usage in Prediction: Similarly, in the
predictmethod, if GPU acceleration is enabled, the feature vectorXis converted to a NumPy arrayself.gpu['xp'].asnumpy(X)before scaling and prediction.
The model is saved using the save_model method within the SignalClassifier module.
Here’s a breakdown of how the model is saved:
- Method Invocation: The
save_modelmethod is called, typically with amodel_pathargument, such as'signal_classifier_model.pkl'. - Model Check: Before attempting to save, the method first checks if a model exists (i.e.,
self.model is None). If no model is present, it prints “No model to save” and does not proceed. - Serialization with
pickle: The core of the saving process involves using thepicklelibrary. The method opens the specifiedmodel_pathin binary write mode ('wb'). - Data to be Saved: It then
pickle.dumps a dictionary containing two key components:- The trained
modelitself (which is aRandomForestClassifierinstance). - The
scaler(which is aStandardScalerinstance). Saving the scaler along with the model ensures that new data can be transformed consistently before prediction, using the same scaling parameters as during training.
- The trained
- Confirmation and Error Handling: Upon successful saving, a confirmation message like “Saved signal classifier model to [model_path]” is printed. The method also includes error handling using a
try-exceptblock to catch and report any issues that might occur during the saving process. - Usage Example: For instance, after a new model is trained by the
train_new_modelfunction,classifier.save_model(model_path)is called to persist the trained model and scaler to a file.
Features are extracted in the SignalClassifier module through a comprehensive process that combines traditional numerical signal analysis with advanced visual analysis performed by a Vision LLM. This is primarily handled by the extract_features method.
Here’s a detailed breakdown of how features are extracted:
- Initialization and GPU Acceleration Check:
- When a
SignalClassifieris initialized, it sets up GPU processing by attempting to importcupy. Ifcupyis available,self.xpis set tocupyfor GPU-accelerated operations; otherwise, it defaults tonumpyfor CPU processing. - The
extract_featuresmethod uses thisself.xpto perform array operations, ensuring that calculations are done on the GPU if enabled.
- When a
- Input Data:
- The
extract_featuresmethod takes frequency (freqs) and amplitude (amplitudes) data as its primary input. - It can optionally take a
spectrogram_pathif visual features are to be extracted.
- The
- Numerical Feature Extraction (Base Features):
- The input
freqsandamplitudesare converted toself.xparrays to leverage GPU acceleration if available. - Peak Detection: It identifies signal peaks. If GPU is enabled, it uses
self.xp.wherefor peak detection based on athreshold. If GPU is not available, it falls back toscipy.signal.find_peaks. - Calculation of various metrics:
- Bandwidth: Calculated from the spread of frequencies above a certain power threshold (3dB below the strongest peak).
- Center Frequency: The frequency corresponding to the strongest peak.
- Peak Power: The amplitude of the strongest peak.
- Mean Power: The average amplitude of the signal.
- Variance: A measure of the spread of amplitudes.
- Skewness: Measures the asymmetry of the amplitude distribution.
- Kurtosis: Measures the “tailedness” of the amplitude distribution.
- Crest Factor: The ratio of the peak amplitude to the mean power.
- Spectral Flatness: Measures how flat or spiky the spectrum is.
- Spectral Rolloff: The frequency below which 85% of the total spectral energy is contained.
- If no peaks are found, default values (mostly zeros) are assigned to these base features.
- The input
- Visual Feature Extraction (LLM-Derived Features):
- This process is initiated if a
spectrogram_pathis provided and the file exists. - Spectrogram Generation: If a spectrogram path is not initially provided, the
predictmethod will first callgenerate_spectrogram_imageto create a PNG image of the RF spectrogram from the frequency and amplitude data. - LLM Processing: The
process_spectrogrammethod is then called, which:- Checks a visual cache: To avoid redundant LLM calls for the same spectrogram within a 10-second window, it first checks a cache.
- Image Preparation: Opens the spectrogram image, converts it to RGB, saves it to an in-memory buffer as a PNG, and then base64 encodes it.
- LLM Query: Sends a request to a locally hosted Vision LLM (
self.vllm_endpoint) with the base64-encoded image and a specific prompt. The prompt asks the LLM to extract:- Frequency markers.
- Number of signal peaks (
visual_peak_count). - Bandwidth (
visual_bandwidth). - Symmetry (
visual_symmetry: symmetric or asymmetric sidebands). - Modulation pattern (
visual_modulation: e.g., sinc-like, dual peaks). - Anomalies (e.g., interference, scintillation).
- Response Handling: The LLM is requested to return results in JSON format. The parsed JSON response is then cached and returned.
- These LLM-derived features are stored as
visual_bandwidth,visual_peak_count,visual_symmetry(1.0 for symmetric, 0.0 for asymmetric),anomalies, andvisual_modulation.
- This process is initiated if a
- Feature Combination:
- The numerical
base_featuresand the LLM-derivedvisual_featuresare combined into a single dictionary. - The complete set of feature names used for the model includes: ‘bandwidth’, ‘center_freq’, ‘peak_power’, ‘mean_power’, ‘variance’, ‘skewness’, ‘kurtosis’, ‘crest_factor’, ‘spectral_flatness’, ‘spectral_rolloff’, ‘visual_bandwidth’, ‘visual_peak_count’, and ‘visual_symmetry’.
- The numerical
- Feature Vector Conversion:
- Finally, the
features_to_vectormethod converts this combined feature dictionary into a NumPy array (vector) in the predefined order ofself.feature_names. This vector is then ready to be scaled and fed into theRandomForestClassifierfor training or prediction.
- Finally, the
The SignalClassifier module’s primary function is to classify RF signals into various modulation types.
This classification is achieved using a RandomForestClassifier, which is further enhanced by a vision LLM (Large Language Model) for spectrogram analysis. The module is designed to support GPU acceleration for signal processing and is intended for integration with RF SCYTHE for applications in naval and Starship contexts.
In essence, it takes RF signal data, extracts features (both numerical and visual from spectrograms via the LLM), and then predicts the modulation type, such as Amplitude Modulation (AM), Frequency Modulation (FM), Single Sideband (SSB), Continuous Wave (CW), Phase Shift Keying (PSK), Frequency Shift Keying (FSK), or identifies it as Noise or Unknown.
Spectrograms are analyzed primarily through visual feature extraction performed by a Vision Large Language Model (LLM). This process is managed by the SignalClassifier module and aims to extract visually identifiable characteristics of RF signals.
Here’s a breakdown of how spectrograms are analyzed:
- Spectrogram Generation:
- If a spectrogram image is not already provided, the
generate_spectrogram_imagemethod creates one from the input frequency and amplitude data. This image, typically a PNG, visualizes the RF signal’s power over frequency. - This dynamically generated spectrogram image is then used for the visual analysis by the LLM.
- If a spectrogram image is not already provided, the
- Visual Cache Utilization:
- Before sending a spectrogram to the Vision LLM for analysis, the
process_spectrogrammethod first checks avisual_cache. - This cache stores previously analyzed spectrogram data along with a timestamp.
- If the current time is within 10 seconds of when data was last cached and data exists in the cache, the cached results are returned immediately. This prevents redundant calls to the Vision LLM for recently analyzed or identical spectrograms, optimizing performance.
- Before sending a spectrogram to the Vision LLM for analysis, the
- Processing by Vision LLM:
- If the spectrogram is not found in the cache or is too old, the
process_spectrogrammethod proceeds to send it to a locally hosted Vision LLM endpoint (self.vllm_endpoint). - The spectrogram image (opened via
PIL.Image) is converted to RGB format and saved into an in-memory buffer as a PNG image. - This image data is then base64 encoded to be included in the request payload for the LLM.
- A specific text prompt is crafted and sent to the LLM along with the encoded image. The prompt instructs the LLM to extract the following information from the spectrogram:
- Frequency markers (e.g., MHz labels).
- Number of signal peaks.
- Bandwidth (width of the main signal in Hz).
- Symmetry (whether sidebands are symmetric or asymmetric).
- Modulation pattern (e.g., sinc-like, dual peaks).
- Anomalies (e.g., interference, scintillation).
- The LLM is requested to return its analysis in JSON format.
- If the spectrogram is not found in the cache or is too old, the
- Response Handling and Feature Integration:
- Upon receiving a response from the LLM, the
process_spectrogrammethod parses the JSON result. - The successful LLM analysis result is then updated in the
visual_cachewith the current timestamp. - The extracted visual data, such as
visual_bandwidth,visual_peak_count,visual_symmetry(converted to 1.0 for symmetric, 0.0 for asymmetric),anomalies, andvisual_modulation, are then combined with the numerically extracted base features. - In case of an error during LLM processing, the system attempts to return any existing cached data.
- Upon receiving a response from the LLM, the
- LLM Validation of Predictions:
- During the final prediction step, the
SignalClassifierutilizes thevisual_modulationextracted by the LLM to potentially validate or adjust the confidence of the model’s prediction. For instance, if the LLM identifies a “sinc-like” pattern (suggesting PSK) but the RandomForestClassifier predicts a different modulation, the confidence of the prediction may be reduced. TheSignalClassifiermodule is designed to classify RF signals and supports integration with RF SCYTHE. This integration specifically allows for naval and Starship applications.
- During the final prediction step, the