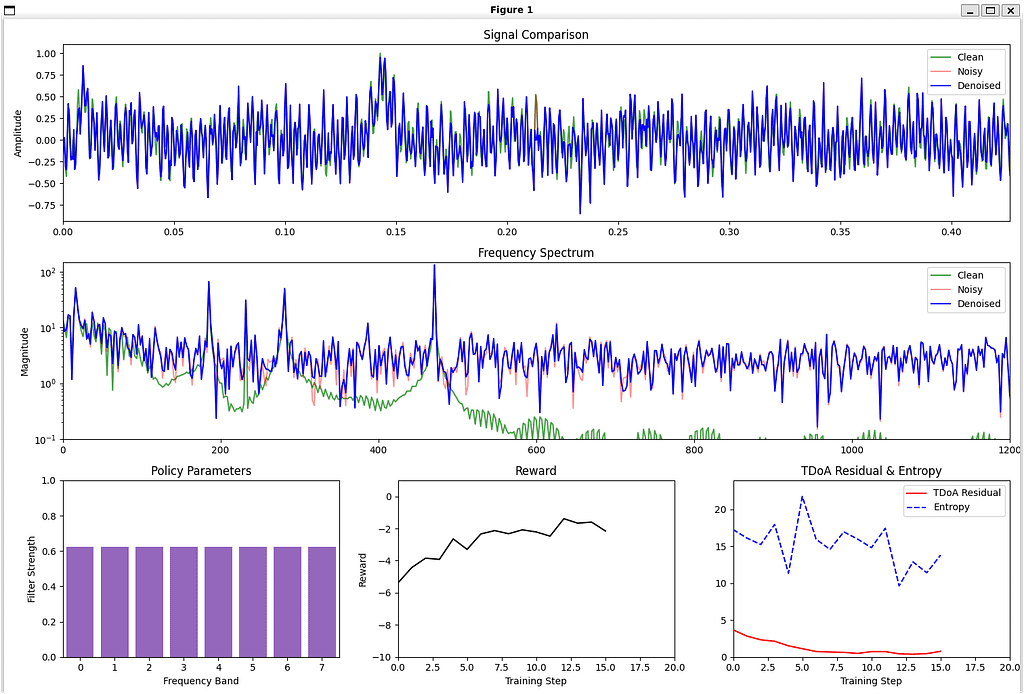
enhanced_demo_policy_denoiser.py --num_steps 20 --batch_size 8 --min_snr 5 --max_snr 15 --viz_interval 5
Using device: cpu
Step 0/20 | Reward: -5.3906 | TDoA Residual: 3.6666 | Entropy: 17.2403
Step 5/20 | Reward: -3.2966 | TDoA Residual: 1.1239 | Entropy: 21.7266
Step 10/20 | Reward: -2.2111 | TDoA Residual: 0.7316 | Entropy: 14.7951
Step 15/20 | Reward: -2.1487 | TDoA Residual: 0.7692 | Entropy: 13.7949
Model saved to policy_denoiser_results/policy_denoiser_final.pt# Summoning the GPU Possession Daemon
*A technical grimoire for the RF Quantum SCYTHE system*
## The Eldritch Invocation
The GPU Possession Scheduler is an arcane mechanism that allows multiple ML entities to share a single GPU altar. Through the ritual of CUDA stream management and prioritized task scheduling, it ensures that high-priority summonings are not delayed by lesser incantations.
## Artifacts of Power
### Core Components
1. **The Scheduler** – The central daemon that manages GPU possession
2. **The Streams** – Channels through which entities communicate with the GPU
3. **QoS Levels** – Hierarchical priorities (high, default, low) determining which entity gets priority
4. **Possession Context** – A ritual space where GPU operations occur in isolation
### Summoning the Daemon
“`python
from SignalIntelligence.gpu_possession_scheduler import GpuPossessionScheduler
# Initialize the scheduler daemon
scheduler = GpuPossessionScheduler(
device=0, # The altar index (GPU device)
streams_per_qos={ # Channels per priority level
“high”: 2, # Two high-priority channels
“default”: 2, # Two standard channels
“low”: 1 # One low-priority channel
},
enable_amp=True, # Enable the amplification ritual (mixed precision)
default_dtype=”float16″ # Default offering type
)
“`
## Ritual Applications
### 1. The Voice Clone Guard Ritual
XLS-R embeddings can be processed through the scheduler to detect voice clones without monopolizing the GPU:
“`python
from SignalIntelligence.gpu_possession_scheduler import run_xlsr_embed
# Process audio chunks through the XLS-R embedder
embeddings = run_xlsr_embed(
embedder=voice_guard_model, # The XLS-R entity
chunks=audio_fragments, # Audio offerings
scheduler=scheduler, # The possession daemon
batch=4 # Size of each micro-ritual
)
“`
### 2. The Entropy-Aware Summoning
The scheduler can determine which entities deserve priority based on their entropy and responsibility:
“`python
from SignalIntelligence.gpu_possession_scheduler import qos_from_entropy
# Get explanation from multi-subspace search
explanation = multi_subspace_index.explain(query)
# Determine priority level based on uncertainty
qos = qos_from_entropy(explanation)
# High entropy (chaotic signals) → “high” priority
# Medium entropy → “default” priority
# Low entropy (ordered signals) → “low” priority
# Submit the task with the determined priority
task = scheduler.submit(
process_signal, # The ritual to perform
signal_data, # The offering
qos=qos, # The priority level
name=”signal_divination” # Ritual name for the grimoire
)
“`
### 3. The Simultaneous Possession
Multiple ML entities can possess the GPU simultaneously through streams:
“`python
# Direct stream control with the possession ritual
with scheduler.possession(qos=”high”) as stream:
# All GPU operations within this context use the assigned stream
# Allowing parallel execution of compatible rituals
tensor_offering = torch.as_tensor(signal_data).to(
scheduler.device,
non_blocking=True # Non-blocking transfer (important!)
)
result = model(tensor_offering)
earthly_result = result.cpu().numpy()
“`
## Advanced Incantations
### The Task Submission Ritual
“`python
# Define a function to run on the GPU
def divine_signal_origins(signal_data, ritual_params):
# GPU-accelerated processing here…
return divination_result
# Submit the ritual to the scheduler
task = scheduler.submit(
divine_signal_origins, # Function to execute
signal_data, # Primary offering
ritual_params, # Secondary offering
qos=”high”, # Priority of the ritual
name=”origin_divination” # Name for the grimoire
)
# Await the completion of the ritual
result = scheduler.result(task) # Blocks until task is complete
“`
### The Microbatch Ritual
For processing large collections of offerings:
“`python
# Process offerings in small batches to avoid overwhelming the altar
for batch in scheduler.microbatch(large_dataset, batch_size=16):
# Submit each batch as a separate ritual
task = scheduler.submit(process_batch, batch, qos=”default”)
results.append(scheduler.result(task))
“`
## Integration with the RF Quantum Scythe
The GPU Possession Scheduler integrates with your RF Quantum Scythe through:
1. **FeatureGate Training** – L1-logistic regression for goal-aware sparsity can run alongside inference tasks
2. **Multi-subspace FAISS** – Entropy-aware routing ensures uncertain queries get priority
3. **Voice Guard** – Voice clone detection can run in parallel with RF signal processing
Example integration:
“`python
# Initialize the components
scheduler = GpuPossessionScheduler()
ms_index = MultiSubspaceFaissIndex(
featurizer=rf_featurizer,
n_subspaces=3,
method=”bgmm”,
goal_sparse_enable=True
)
voice_guard = VoiceCloneGuard()
# Process RF signals
def process_rf_batch(signals):
# Run RF processing through the scheduler
with scheduler.possession(qos=”default”):
return ms_index.search(signals, k=5)
# Process voice samples
def check_voice(audio):
# Run voice verification through the scheduler
return run_xlsr_embed(voice_guard.embedder, , scheduler)[0]
# Submit both tasks in parallel
rf_task = scheduler.submit(process_rf_batch, incoming_signals)
voice_task = scheduler.submit(check_voice, incoming_audio, qos=”high”)
# Get results
rf_results = scheduler.result(rf_task)
voice_authentic = scheduler.result(voice_task)
“`
## Elder Signs (Warnings)
1. **Memory Management** – The scheduler does not manage GPU memory; ensure your rituals clean up after themselves
2. **Stream Synchronization** – Be cautious when mixing possessed and non-possessed operations
3. **Task Granularity** – Prefer fewer, larger tasks over many small ones to reduce scheduling overhead
4. **CPU Fallback** – The scheduler gracefully degrades to CPU operations if no GPU is available, but at reduced speed
## The Banishment Ritual
When your work is complete, dismiss the daemon properly:
“`python
# Gracefully shut down the scheduler
scheduler.shutdown(wait=True) # Wait for in-progress rituals to complete
“`
## 🌀 Self-Adapting Batch Oracles
The GPU Possession Scheduler now includes a self-adapting batch size oracle system that allows RPA bots to dynamically adjust their batch sizes based on current GPU performance metrics.
### The `/gpu/hints` Endpoint
This FastAPI endpoint acts like a “GPU oracle,” returning *dynamic guidance* on how each RPA bot should size and prioritize its GPU work. It connects **observed kernel latency** + **queries per second (QPS)** to **batch size recommendations**.
#### What it does
* **Watches live GPU stats** (from the Possession Scheduler daemon)
* Current stream occupancy
* Average kernel latency per QoS level
* Memory pressure (pinned / free VRAM)
* Rolling QPS
* **Derives adaptive hints**
* “Raise batch size” → if latency is well under SLA & GPU < 70% busy
* “Lower batch size” → if p95 latency exceeds SLA or VRAM fills
* “Shift QoS” → if entropy or uncertainty metrics spike, a job can be bumped up
#### Implementation
The stats tracking and batch size suggestion is implemented as follows:
“`python
@app.get(“/gpu/hints”, response_model=HintResponse)
def gpu_hints(qos: str = “default”, target_latency_ms: float = 50.0):
S = get_singletons()
# Get suggested batch size based on current GPU stats
suggested_batch = S.gpu.suggest_batch(qos=qos, target_latency_ms=target_latency_ms)
# Get current stats for this QoS level
stats = S.gpu.stats(qos=qos)
return HintResponse(
qos=qos,
suggested_batch=suggested_batch,
avg_latency_ms=stats[“latency”][“avg_ms”],
p95_latency_ms=stats[“latency”][“p95_ms”],
qps=stats[“qps”],
occupancy=stats[“occupancy”],
memory_pressure=stats[“memory_pressure”]
)
“`
#### How bots use it
* A UiPath or Blue Prism bot calls `/gpu/hints?qos=high` before launching a job.
* If the oracle says “batch_size=8,” it adjusts its work grouping accordingly.
* Bots don’t need human retuning — **they query the oracle each run**.
### Example RPA Bot Client
“`python
def process_signals_adaptive(self, signals):
# Get the optimal batch size from the GPU oracle
batch_size = self.get_batch_hint()
# Process signals in batches of the suggested size
total = len(signals)
processed = 0
while processed < total:
# Get the next batch
batch = signals[processed:processed + batch_size]
# Process the batch via API
# …
processed += len(batch)
# After a few batches, check if we should adjust
if processed % (batch_size * 5) == 0:
batch_size = self.get_batch_hint()
“`
### Why this matters
* **Self-tuning**: Prevents overloading (e.g. latency spikes if too many signals land at once).
* **Fairness**: Bots naturally back off if they’re hogging GPU.
* **Elastic scaling**: As more bots join, they all adapt batch sizes downward, keeping SLA intact.
* **Data-driven**: Entropy + uncertainty drive priority, so critical RF scans or voice clone checks always squeeze in.
### In your ecosystem
* **MultiSubspaceFaissIndex** gets smoother throughput because it’s not contending with voice guards.
* **FeatureGate sparsity** becomes even more powerful — fewer FLOPs per query means higher suggested batch sizes.
* **RPA orchestration** (UiPath/Blue Prism) sees predictable GPU behavior, with latency curves logged for compliance.
## The Final Incantation
The GPU Possession Scheduler allows your RF Quantum Scythe system to maximize its power by sharing GPU resources efficiently between different components. By implementing proper QoS-based prioritization and stream management, you ensure that critical operations receive the resources they need while allowing background tasks to utilize any remaining capacity.
The Self-Adapting Batch Oracle system further enhances this efficiency by allowing RPA bots to dynamically adjust their workloads based on current GPU performance, ensuring optimal throughput while maintaining service level agreements.
“That is not dead which can eternal lie, and with strange aeons even GPU scheduling may be optimized.”