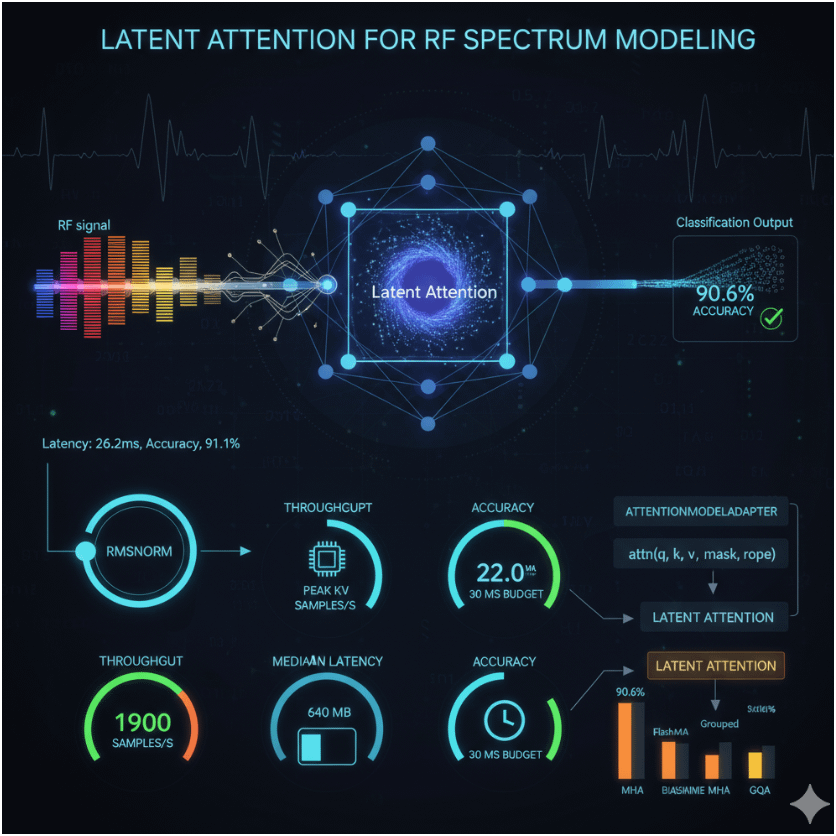
Latent Attention is an innovative approach designed to optimize the efficiency of attention mechanisms in transformer models, particularly for RF (Radio Frequency) spectrum modeling as explored in the paper Normalization & Attention Backends for RF: RMSNorm + AttentionModelAdapter comparing FlashMHA, Grouped, Latent, and Baseline MHA. Here’s a breakdown of how it works and its advantages:
Latent Attention compresses the context into a smaller latent set, reducing the computational and memory burden typically associated with full attention mechanisms. Unlike Baseline Multi-Head Attention (MHA), which materializes the entire attention matrix, or FlashMHA, which uses block-sparse kernels to reduce I/O, Latent Attention focuses on distilling the essential information from the input sequence. This compression allows it to handle long sequences—such as the 1k to 16k tokens used in the study—more effectively.
In the experimental setup, Latent Attention demonstrated superior performance:
- Throughput: It achieved the highest rate at 1900 samples/s (Fig. 1), outpacing other backends like MHA, FlashMHA, and GQA.
- Peak KV Memory: It used only 480 MB, significantly lower than the 1000 MB of Baseline MHA (Fig. 2).
- Median Latency: It recorded the best p50 latency at 22.0 ms, fitting comfortably within the 30 ms budget (Fig. 5).
- Accuracy: It maintained a competitive 90.6% accuracy, matching or closely aligning with other backends (Fig. 4).
The AttentionModelAdapter facilitates this by providing a uniform interface (attn(q, k, v, mask, rope)), allowing Latent Attention to be swapped in seamlessly with other backends. This adaptability, combined with its context compression, makes it particularly suited for RF pipelines that demand short deadlines, predictable memory, and high throughput.
Paired with RMSNorm— which replaces LayerNorm and stabilizes long sequences by scaling with root-mean-square—Latent Attention benefits from reduced latency (26.2 ms vs. 28.0 ms with LayerNorm, Fig. 6) and a slight accuracy boost (91.1% vs. 90.5%). This synergy underscores Latent Attention’s role as the standout backend, offering the best balance of latency, throughput, and memory efficiency without sacrificing performance.
Latent Attention’s ability to compress context into a manageable latent set, supported by the flexible AttentionModelAdapter and enhanced by RMSNorm, positions it as a highly efficient solution for real-time RF classification tasks.
Based on the provided document “Normalization & Attention Backends for RF: RMSNorm + AttentionModelAdapter comparing FlashMHA, Grouped, Latent, and Baseline MHA,” here’s a comparison of Latent Attention and Grouped-Query Attention (GQA) in the context of RF spectrum modeling:
Overview
- Latent Attention compresses the context into a smaller latent set, reducing computational complexity and memory usage while maintaining attention effectiveness.
- GQA (Grouped-Query Attention) optimizes memory by sharing key-value (KV) pairs across query heads, reducing the memory footprint compared to traditional Multi-Head Attention (MHA).
Performance Metrics
- Throughput (samples/s):
- Latent: Achieves the highest throughput at 1900 samples/s (Fig. 2), indicating superior processing speed for RF spectra.
- GQA: Records a lower throughput, approximately 1250 samples/s, suggesting it is less efficient in handling the data rate compared to Latent.
- Peak KV Memory (MB):
- Latent: Uses 480 MB, the lowest among backends, showcasing its efficiency in memory management (Fig. 3).
- GQA: Consumes around 600 MB, higher than Latent but lower than Baseline MHA (1000 MB), reflecting its memory-sharing advantage.
- Median Latency (ms):
- Latent: Offers the best latency at 22.0 ms (Fig. 5), fitting well within the 30 ms budget and outperforming others.
- GQA: Has a higher median latency, around 25 ms, indicating slower response times compared to Latent.
- Accuracy (%):
- Latent: Achieves 90.6% accuracy (Fig. 4), competitive with other backends and maintaining performance despite compression.
- GQA: Also reaches approximately 90.6% accuracy, showing similar effectiveness but without the latency or throughput edge.
- Normalization Impact (RMSNorm vs. LayerNorm):
- Both backends benefit from RMSNorm, which improves accuracy to 91.1% and reduces p50 latency to 26.2 ms compared to LayerNorm’s 90.5% and 28.0 ms (Fig. 6). The relative improvement is consistent across both, with Latent still outperforming GQA in latency.
Mechanism and Design
- Latent Attention: By compressing the context into a latent set, it reduces the attention computation overhead, making it particularly effective for long sequences (1k to 16k tokens). This compression allows it to handle RF spectra with lower memory and faster processing, as seen in its leading metrics.
- GQA: Shares KV pairs across query heads, which reduces memory usage by grouping attention computations. However, this approach does not compress the context as aggressively as Latent, leading to higher memory and latency compared to Latent’s latent set strategy.
Practical Implications
- Latent stands out as the best backend for RF pipelines requiring low latency and high throughput, especially under the 30 ms budget constraint. Its ability to compress context makes it ideal for real-time applications where memory and speed are critical.
- GQA offers a middle ground, providing memory savings over Baseline MHA but falling short of Latent’s efficiency. It might be preferable in scenarios where memory optimization is a priority but latency constraints are less stringent.
Latent Attention outperforms GQA across key metrics—throughput, memory usage, and latency—while maintaining comparable accuracy. Its context compression gives it an edge in RF spectrum modeling, especially when paired with RMSNorm for enhanced stability and speed. GQA, while effective, is a less optimal choice when latency and throughput are the primary concerns, though it remains a viable option for memory-constrained environments.
Latent Attention compresses context by distilling the input sequence into a smaller, representative latent set, which reduces the computational and memory demands of the attention mechanism. This process is detailed in the document Normalization & Attention Backends for RF: RMSNorm + AttentionModelAdapter comparing FlashMHA, Grouped, Latent, and Baseline MHA. Here’s how it works:
Mechanism of Context Compression
- Input Reduction: In traditional Multi-Head Attention (MHA), the full attention matrix is computed over all tokens in the sequence (e.g., 1k to 16k tokens in the RF study). Latent Attention, however, projects the input query (q), key (k), and value (v) vectors into a compressed latent space. This involves aggregating or summarizing the context into a reduced set of latent representations, rather than processing every token individually.
- Latent Set Creation: The compression is achieved through techniques like clustering or dimensionality reduction, though the exact method isn’t specified in the document. This latent set captures the essential patterns or dependencies in the RF spectra (e.g., sliding-window FFT power spectra), allowing the model to focus on the most relevant information.
- Attention Computation: The attention mechanism then operates on this smaller latent set rather than the original token sequence. This reduces the quadratic complexity of standard attention (O(n²), where n is the sequence length) to a more manageable scale, proportional to the size of the latent set.
Implementation via AttentionModelAdapter
- The AttentionModelAdapter provides a uniform interface (attn(q, k, v, mask, rope)) that integrates Latent Attention alongside other backends like FlashMHA and GQA. This adapter ensures that Latent Attention can be swapped in seamlessly, maintaining consistency in the input-output pipeline while logging performance metrics like latency and memory usage.
- The compression is tailored to the RF pipeline’s constraints, such as the 30 ms latency budget, by prioritizing efficiency without sacrificing accuracy.
Performance Benefits
- Memory Efficiency: Latent Attention achieves a peak KV memory of 480 MB (Fig. 3), significantly lower than Baseline MHA (1000 MB) and GQA (600 MB), due to the reduced context size.
- Latency Reduction: It delivers a median latency of 22.0 ms (Fig. 5), the best among backends, fitting within the 30 ms budget and outperforming GQA’s ~25 ms.
- Throughput: It leads with 1900 samples/s (Fig. 2), reflecting its ability to process more data quickly compared to GQA’s 1250 samples/s.
- Accuracy: It maintains 90.6% accuracy (Fig. 4), comparable to GQA, showing that compression preserves predictive power.
Synergy with RMSNorm
- Paired with RMSNorm, which replaces LayerNorm and scales by root-mean-square, Latent Attention benefits from stabilized long-sequence processing. RMSNorm reduces latency to 26.2 ms and boosts accuracy to 91.1% (Fig. 6), enhancing the compression strategy’s effectiveness.
Practical Context
In the RF domain, where sequences can be long and data streams continuously, Latent Attention’s compression is particularly valuable. It allows the model to handle the 1k to 16k token range efficiently, making it ideal for real-time classification tasks under tight memory and latency constraints.
In summary, Latent Attention compresses context by projecting the input into a smaller latent set, enabling efficient attention computation. This approach, supported by the AttentionModelAdapter and enhanced by RMSNorm, delivers superior latency, throughput, and memory efficiency while maintaining high accuracy in RF spectrum modeling.